Web scraping is a powerful technique used for data extraction from websites, enabling users to gather valuable information quickly and efficiently. As online content continues to grow exponentially, mastering web scraping techniques becomes increasingly essential for businesses and researchers alike. This guide not only covers the fundamental aspects of web scraping but also emphasizes the importance of ethical web scraping practices to ensure compliance with legal standards. Additionally, we highlight strategies for maintaining data quality throughout the scraping process, which is crucial for reliable analysis. By adhering to scraping best practices, both novices and seasoned professionals can significantly enhance their data collection efforts.
In the realm of data acquisition, web scraping stands out as a vital tool that facilitates automated data gathering from the internet. Often referred to as web harvesting or web data extraction, this process allows users to capture large volumes of information from various online sources seamlessly. As the digital landscape evolves, understanding the nuances of these data extraction methods becomes critical for effective information utilization. This article will delve into the essential techniques, ethical considerations, and quality assurance measures that define successful data scraping endeavors. Whether you’re new to this field or looking to refine your skills, our comprehensive guide aims to equip you with the knowledge necessary to excel in your data scraping projects.
Understanding Web Scraping: An Overview
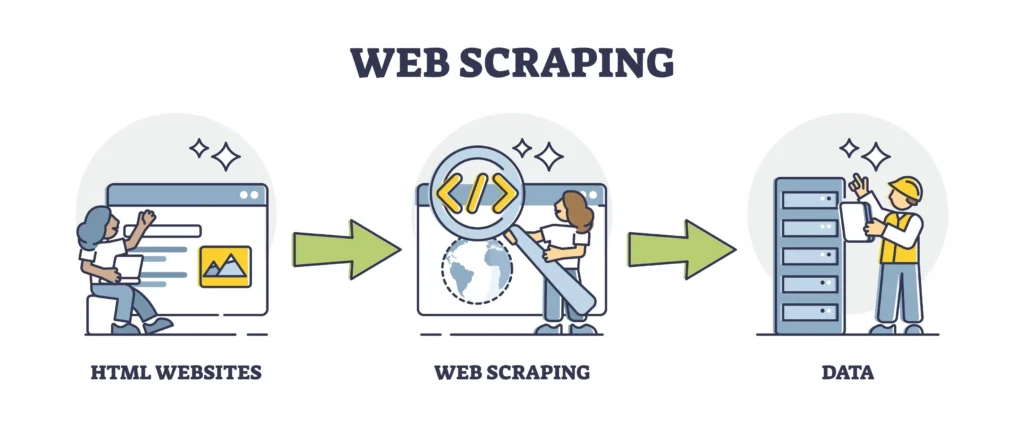
Web scraping is a powerful technique used to extract large amounts of data from websites quickly and efficiently. By utilizing various web scraping techniques, individuals and organizations can gather information from multiple sources, enabling them to make data-driven decisions. This process involves retrieving web pages, parsing the HTML or XML content, and extracting relevant data points. As the digital landscape continues to expand, mastering web scraping has become essential for anyone looking to acquire useful data.
In essence, web scraping serves as a bridge between unstructured data available on the internet and structured data that can be used for analysis. With the right tools and methodologies, web scraping allows users to collect valuable information from diverse formats, whether it be text, images, or tables. Understanding the fundamentals of web scraping is crucial for anyone interested in data extraction, as it lays the groundwork for more advanced techniques and applications.
Ethical Considerations in Web Scraping
When engaging in web scraping, it’s imperative to consider the ethical implications associated with this practice. Ethical web scraping involves respecting the terms of service of websites, which often explicitly prohibit automated data collection. Ignoring these guidelines can lead to legal repercussions and damage a company’s reputation. Moreover, ethical web scraping promotes a fair use of data, ensuring that the rights of website owners and users are respected.
Additionally, ethical considerations extend to how the collected data is used. Organizations must ensure that the data extraction process does not violate privacy rights or misuse sensitive information. By following ethical guidelines and best practices, web scrapers can maintain integrity and foster trust within the digital ecosystem. This commitment to ethical practices not only protects individuals and businesses but also contributes to a more sustainable online environment.
Best Practices for Effective Web Scraping
Implementing best practices in web scraping is essential for ensuring data quality and reliability. One of the key best practices is to regularly check the target website for any changes in structure or content, as these can impact the scraping process. Keeping your scraping tools updated and adapting to changes will help in maintaining the accuracy of the extracted data. Furthermore, it is advisable to employ techniques like rate limiting to avoid overwhelming the target server, which can lead to temporary bans or IP blacklisting.
Another important aspect of best practices is to document the scraping process thoroughly. This documentation should include details about the tools used, the data sources, and any transformations applied to the data. Such practices not only enhance transparency but also facilitate troubleshooting and future updates. By adhering to these best practices, web scrapers can ensure high-quality data extraction while minimizing potential risks associated with scraping.
Web Scraping Techniques for Beginners
For beginners, understanding the various web scraping techniques is crucial for effective data extraction. One common method is using libraries such as Beautiful Soup or Scrapy in Python, which allow users to parse HTML content and extract relevant data easily. These libraries provide intuitive functions for navigating the document tree, making it easier for novices to get started with web scraping projects. Additionally, using browser automation tools like Selenium can be beneficial for scraping dynamic websites that require interaction.
Another technique involves using APIs provided by websites, which offer a more structured way to access data without the need for scraping. APIs typically return data in formats like JSON or XML, making it easier to work with than raw HTML. Beginners should explore both scraping and API integration to determine the best approach for their specific needs. By familiarizing themselves with these techniques, new scrapers can build a solid foundation for more advanced data extraction tasks.
Ensuring Data Quality in Web Scraping
Data quality is paramount in web scraping, as inaccurate or incomplete data can lead to flawed analysis and decision-making. To ensure high data quality, scrapers should implement validation checks during the extraction process. This can involve verifying that the data collected matches expected formats or ranges and filtering out any duplicates or irrelevant information. Regular audits of the scraped data can also help identify inconsistencies and areas for improvement.
Moreover, utilizing machine learning techniques can significantly enhance data quality in web scraping. By applying algorithms to clean and preprocess the data, scrapers can improve its accuracy and usability. Incorporating data validation methods such as cross-referencing with reliable sources can further bolster the integrity of the extracted information. Prioritizing data quality not only improves the outcomes of web scraping efforts but also builds credibility and trust in the insights generated.
Advanced Data Extraction Techniques
As web scraping skills develop, individuals may seek to explore advanced data extraction techniques that can enhance their efficiency and effectiveness. One such technique is the implementation of machine learning models to identify patterns and automate the scraping process. This can be particularly useful when dealing with large datasets or when scraping sites with complex structures. By training models to recognize specific data points, scrapers can streamline their efforts and reduce manual intervention.
Another advanced technique is the use of headless browsers for scraping, which allows users to interact with web pages as if they were using a standard browser, but without the graphical interface. This method can be especially beneficial for scraping JavaScript-heavy websites where traditional scraping methods may fall short. By leveraging these advanced data extraction techniques, scrapers can optimize their workflows and achieve more robust results.
The Role of Automation in Web Scraping
Automation plays a crucial role in modern web scraping, enabling users to gather data at a scale and speed that manual methods cannot match. By automating the scraping process, businesses can continuously collect and analyze data, providing real-time insights into market trends and consumer behavior. Tools such as Python scripts or specialized web scraping software can help automate repetitive tasks, allowing scrapers to focus on higher-level analysis and decision-making.
Additionally, automation can enhance the reliability of data extraction by minimizing human error. Automated scripts can be programmed to follow specific protocols, ensuring consistency in how data is collected and processed. However, it’s important to implement safeguards and monitoring systems to oversee automated scraping activities and address any issues promptly. Embracing automation in web scraping not only improves efficiency but also empowers users to leverage data more effectively.
Challenges in Web Scraping and How to Overcome Them
Web scraping often presents several challenges, particularly when it comes to navigating changes in website structures or dealing with anti-scraping measures implemented by site owners. For instance, a website may frequently update its layout, rendering existing scraping scripts ineffective. To overcome this, scrapers should adopt a flexible approach, regularly testing and updating their methods to adapt to such changes.



Additionally, many websites deploy anti-bot technologies that can hinder scraping efforts, such as CAPTCHAs or IP blocking. To combat these challenges, scrapers can employ techniques like rotating proxies and using CAPTCHA-solving services. By proactively addressing these obstacles, web scrapers can ensure that their data extraction processes remain efficient and effective.
Future Trends in Web Scraping
The future of web scraping is poised for significant evolution, driven by advancements in artificial intelligence and machine learning. As these technologies continue to improve, we can expect more sophisticated scraping tools that can intelligently navigate websites, extract data, and even understand context and semantics. This will not only enhance the accuracy of data extraction but also reduce the need for manual intervention, making web scraping more accessible to users of varying skill levels.
Moreover, the growing emphasis on data privacy and ethical considerations will shape the future landscape of web scraping. As regulations around data use become stricter, scrapers will need to adapt by implementing best practices that prioritize ethical data collection and compliance with legal frameworks. By staying informed about these trends and evolving their strategies accordingly, web scrapers can continue to thrive in a rapidly changing digital environment.
Frequently Asked Questions
What is web scraping and how does it relate to data extraction?
Web scraping is the automated process of extracting data from websites. It is a key technique in data extraction, allowing users to gather large volumes of information efficiently. By utilizing various web scraping techniques, individuals and businesses can access structured data from unstructured web sources.
What are the best practices for ethical web scraping?
Ethical web scraping involves respecting website terms of service, avoiding excessive requests that may disrupt server operations, and not collecting personal data without consent. Following these best practices ensures compliance with legal standards and promotes responsible data extraction.
How can I ensure data quality when using web scraping techniques?
To ensure data quality in web scraping, validate extracted data against trusted sources, handle missing or malformed entries, and regularly update your scraping scripts to adapt to changes in website structures. This process helps maintain the integrity and reliability of the gathered information.
What are the common web scraping techniques used for data extraction?
Common web scraping techniques include HTML parsing, DOM manipulation, and API integration. These methods allow scrapers to extract relevant information efficiently from various formats, ensuring comprehensive data extraction from diverse web sources.
What are the potential risks associated with web scraping?
Web scraping can lead to potential risks such as legal issues, IP bans, and data inaccuracies if not done responsibly. To mitigate these risks, adhere to ethical web scraping practices and implement measures like rate limiting and user-agent rotation.

How can beginners get started with web scraping?
Beginners can start with web scraping by learning programming languages such as Python or JavaScript, which offer libraries like BeautifulSoup and Scrapy. These tools simplify data extraction processes and provide a strong foundation for understanding web scraping techniques.
What tools are recommended for effective web scraping?
Recommended tools for effective web scraping include Scrapy, BeautifulSoup, and Selenium. These tools facilitate various web scraping techniques and help ensure high data quality by providing robust frameworks for data extraction.
Is web scraping legal, and how can I ensure compliance?
The legality of web scraping varies by jurisdiction and depends on website terms of service. To ensure compliance, always review the legal framework regarding data extraction in your region and respect the rules set by the websites you are scraping.
| Key Points | Details |
|---|---|
| Definition of Web Scraping | Web scraping is the process of automatically extracting information from websites. |
| Methods of Data Extraction | Various techniques such as using APIs, parsing HTML, and browser automation tools. |
| Handling Formats | Web scraping can deal with different data formats like JSON, XML, and HTML. |
| Data Quality Assurance | Ensuring the accuracy and reliability of the scraped data through validation techniques. |
| Ethical Considerations | Understanding the legal implications and respecting the terms of service of websites. |
| Best Practices | Follow guidelines to avoid IP banning and ensure responsible scraping. |
| Target Audience | This guide is useful for both beginners and experienced web scrapers. |
Summary
Web scraping is a vital skill for anyone looking to gather data efficiently from the web. This guide covers essential methods, ethical practices, and best strategies to enhance your web scraping abilities. By understanding the intricacies of data extraction and ensuring data quality, you can effectively utilize web scraping for your projects.